Analyzing My Music Library with Elasticsearch
Published on
I listen to music a lot. Looking at my iTunes music library the other day, I started making “smart” playlists to classify my music collection per year of albums releases. It’s been a tedious process – and I only went back from 2015 to 1991. Then I realized that the process of classifying and analyzing my music collection could actually be an interesting activity, and I started wondering about how to do it efficiently. Having only used Elasticsearch at work for trivial logs indexing and searching so far, I figured I could use it in a more “advanced” way to help my dig through my gigabytes of music tracks.
Indexing iTunes library into Elasticsearch
In order to search through my music library I first had to extract the tracks metadata from iTunes and index them in Elasticsearch.
The first step was quite simple: extract the library from iTunes in a file library.xml – iTunes menu File > Library > Export Library. The result is a XML Property Lists file that I had to convert into JSON documents indexable by Elasticsearch. A raw library track entry looks like this:
<key>1566</key>
<dict>
<key>Track ID</key><integer>1566</integer>
<key>Name</key><string>Gravity</string>
<key>Artist</key><string>A Perfect Circle</string>
<key>Composer</key><string>Maynard James Keenan, Billy Howerdel, Josh Freese, Troy Van Leeuwen, Paz Lenchantin</string>
<key>Album</key><string>Thirteenth Step</string>
<key>Genre</key><string>Rock</string>
<key>Kind</key><string>MPEG audio file</string>
<key>Size</key><integer>12286195</integer>
<key>Total Time</key><integer>306128</integer>
<key>Disc Number</key><integer>1</integer>
<key>Disc Count</key><integer>1</integer>
<key>Track Number</key><integer>12</integer>
<key>Track Count</key><integer>12</integer>
<key>Year</key><integer>2003</integer>
<key>Date Modified</key><date>2009-11-14T11:46:42Z</date>
<key>Date Added</key><date>2013-04-15T21:12:53Z</date>
<key>Bit Rate</key><integer>320</integer>
<key>Sample Rate</key><integer>44100</integer>
<key>Play Count</key><integer>4</integer>
<key>Play Date</key><integer>3488975157</integer>
<key>Play Date UTC</key><date>2014-07-23T13:45:57Z</date>
<key>Normalization</key><integer>2325</integer>
<key>Artwork Count</key><integer>1</integer>
<key>Sort Artist</key><string>Perfect Circle</string>
<key>Persistent ID</key><string>D9E761709EA898D1</string>
<key>Track Type</key><string>File</string>
<key>Location</key><string>file:///Users/marc/Music/A%20Perfect%20Circle/Thirteenth%20Step/12%20Gravity.mp3</string>
<key>File Folder Count</key><integer>4</integer>
<key>Library Folder Count</key><integer>1</integer>
</dict>
I’ve written a quick’n dirty Python script that parses this file in a trivial and sub-optimal way – especially if like me the exported library file is several megabytes long:
As you can see, it only keeps a few fields from the library tracks metadata – the ones I’ve found relevant to my analysis.
Running the script passing the exported library file as argument generates a library.json file containing as many JSON-formatted lines as there are tracks in the library:
$ ./itunes2json.py library.xml > library.json
$ wc -l library.json
8408 library.json
$ head -n 1 library.json
{"album": "Fight Club", "total_time": 303, "kind": "MPEG audio file", "name": "Who Is Tyler Durden ?", "artist": "The Dust Brothers", "play_count": 2, "bit_rate": 320, "year": "1999", "genre": "Soundtrack", "size": 12239773}
The more efficient way I’ve found to index the JSON documents into Elasticsearch is to use its Bulk API. This method requires a bit of shell scripting to bulk the records:
$ while read track; do
echo '{"index":{"_index":"library","_type":"track"}}'
echo $track
done < library.json > bulk
The library Elasticsearch index settings and mapping for the “track” document type looks like this:
$ cat library.index
{
"settings" : {
"index" : {
"number_of_shards" : 1,
"number_of_replicas" : 0
}
},
"mappings": {
"track": {
"properties": {
"year": { "format": "year", "type": "date" },
"album": { "index": "not_analyzed", "type": "string" },
"artist": { "index": "not_analyzed", "type": "string" },
"genre": { "index": "not_analyzed", "type": "string" },
"kind": { "index": "not_analyzed", "type": "string" },
"name": { "index": "not_analyzed", "type": "string" },
"play_count": { "type": "long" },
"total_time": { "type": "long" },
"bit_rate": { "type": "long" },
"size": { "type": "long"
}
}
}
}
}
# Create the index
$ curl -X PUT -d @library.index localhost:9200/library
{"acknowledged":true}
# Bulk load the documents
$ curl --data-binary @bulk localhost:9200/library/track/_bulk?pretty
...
"create" : {
"_index" : "library",
"_type" : "track",
"_id" : "AVAqUo18SEui9dB0w9wD",
"_version" : 1,
"status" : 201
}
} ]
}
$ curl localhost:9200/library/_stats/docs/?pretty
{
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"_all" : {
"primaries" : {
"docs" : {
"count" : 8392,
"deleted" : 0
}
},
"total" : {
"docs" : {
"count" : 8392,
"deleted" : 0
}
}
},
"indices" : {
"library" : {
"primaries" : {
"docs" : {
"count" : 8392,
"deleted" : 0
}
},
"total" : {
"docs" : {
"count" : 8392,
"deleted" : 0
}
}
}
}
}
You might have noticed than I ended up with fewer documents indexed than expected (8392 instead of 8408): during the bulk indexing some encoding errors occurred, causing Elasticsearch to discard some documents. For instance:
...
"create" : {
"_index" : "library",
"_type" : "track",
"_id" : "AVAqUo1zSEui9dB0w9g8",
"status" : 400,
"error" : "MapperParsingException[failed to parse]; nested: JsonParseException[Unexpected character ('D' (code 68)): was expecting comma to separate OBJECT entries\n at [Source: [B@afbf6; line: 1, column: 100]]; "
}
...
Oh well… Let’s move to the fun part ;)
Analyzing my music collection
First, but that goes without saying: the results obtained are only as good as my music files' metadata, e.g. the ID3 tags for MP3 files. I tried my best to keep them clean and exact, but there might be some inconsistencies here and there.
I’ve used Kibana for the first part of my analysis. When looking up at our indexed documents without any specific query, here is what we can find:

I started with a few visualization widgets summarizing trivial stats on my collection:
Top 10 artists/bands
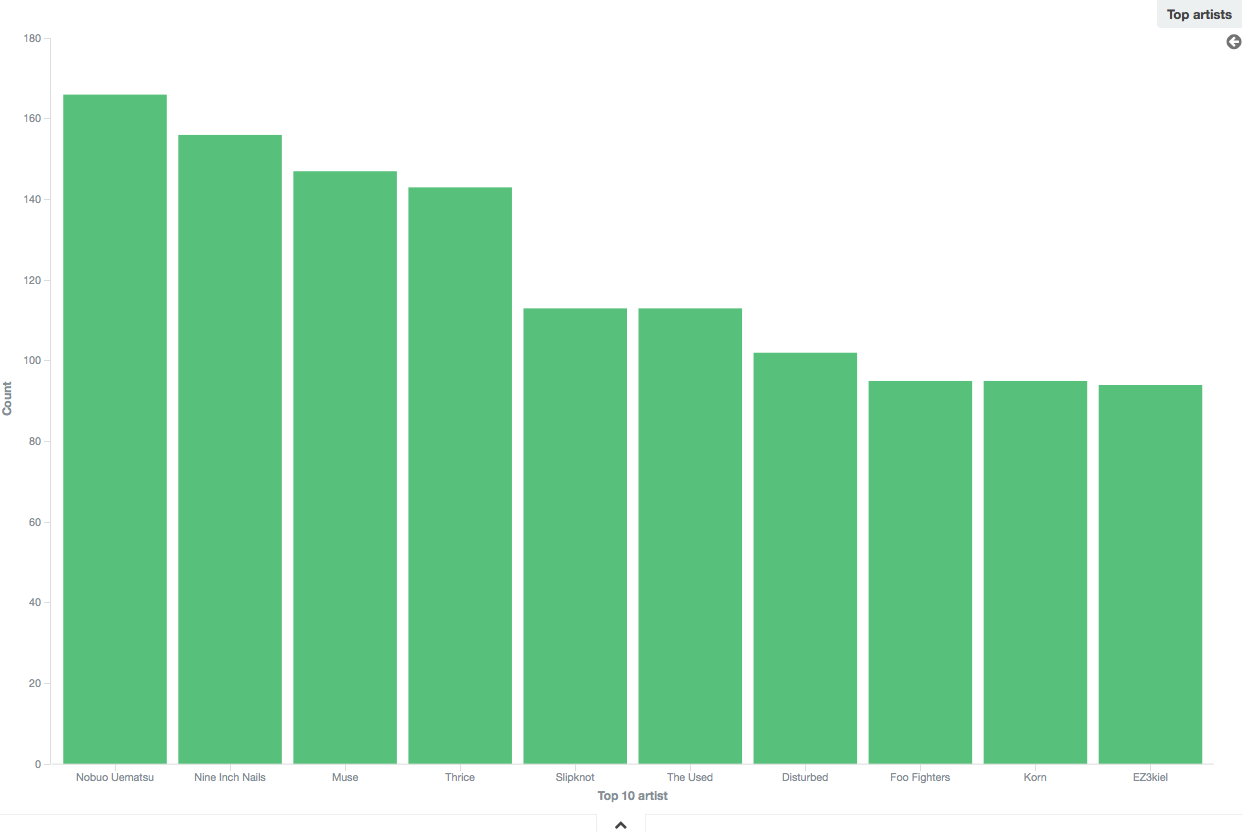
That one was quite a surprise to me: although I used to listen to a lot of Final Fantasy soundtracks, I didn’t expect Nobuo Uematsu to be the most represented artist in my collection.
Distribution per year
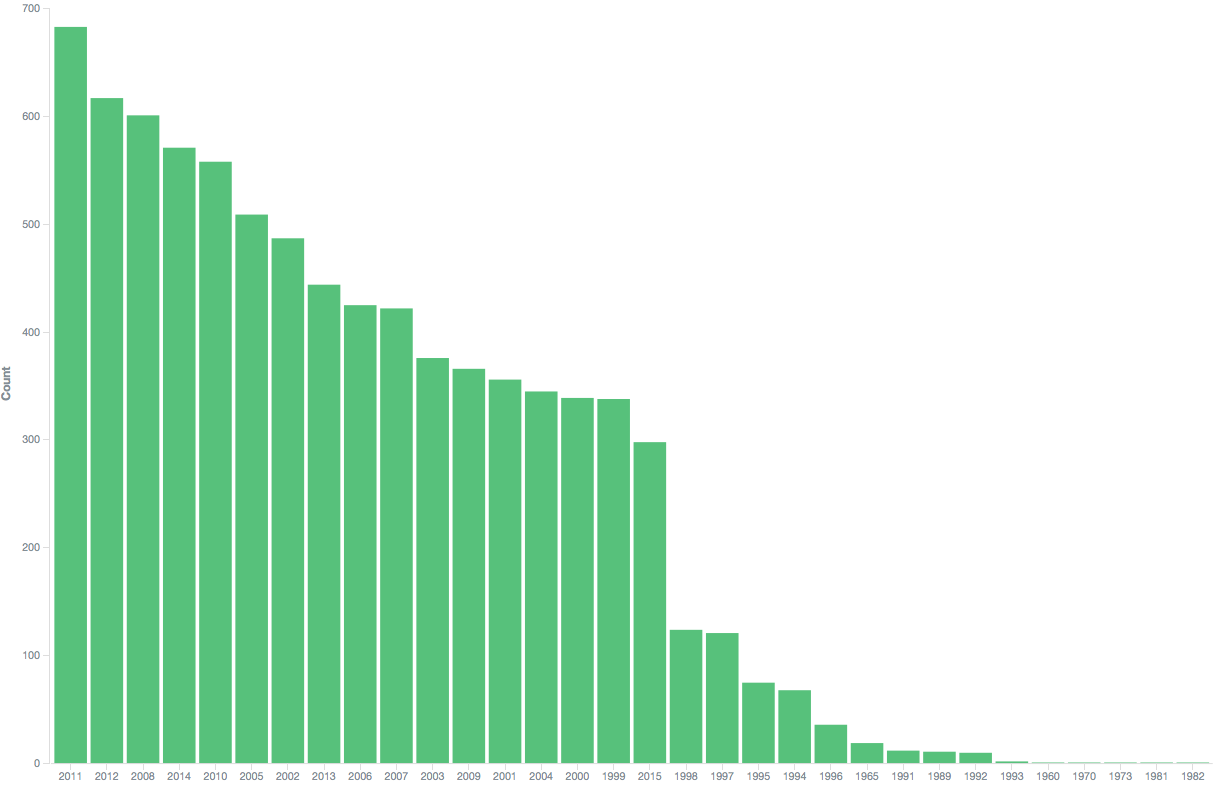
Not much to say here: I tend to listen to fairly recent music.
Top 10 musical genres
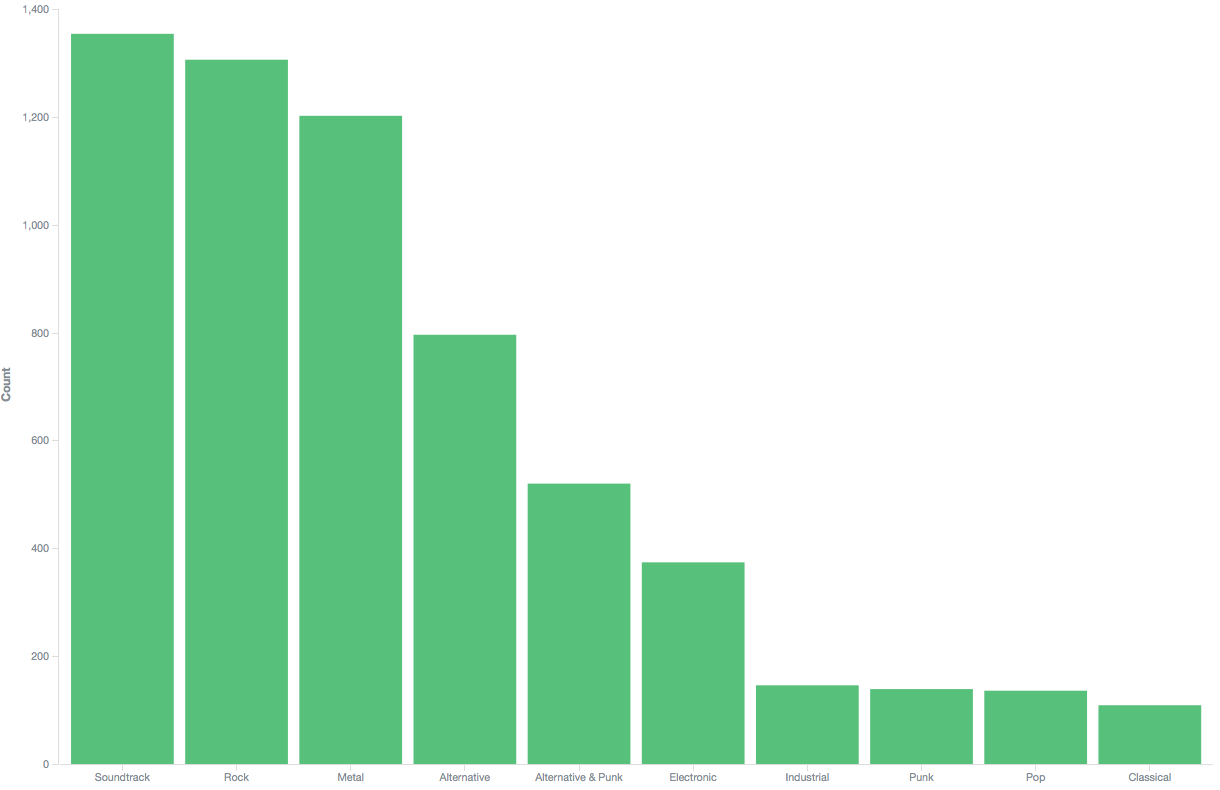
For what it’s worth when trying to classify music into strict genres, the trend is quite clear here: I listen mostly to (movie, video games) soundtracks, Rock and Metal.
File kinds
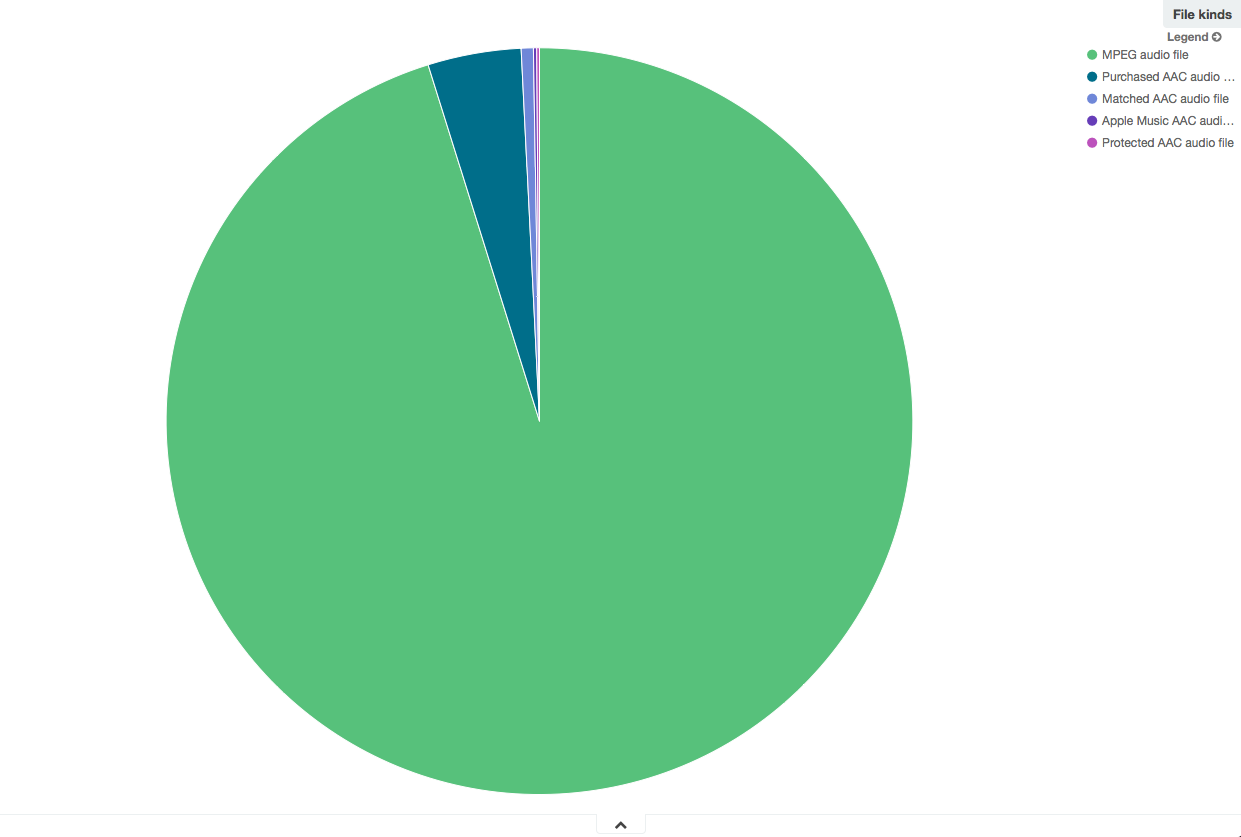
Nothing special to say about this either: my music collection is essentially composed of MP3 ripped from original CD, and a few tracks bought in the Apple iTunes store.
OK, time to level up a bit. The next queries have been made directly via Elasticsearch’s search API – usually leveraging aggregations –, as I haven’t been able to find how to do it using Kibana.
10 Most played tracks
$ curl 'localhost:9200/library/track/_search?q=*&sort=play_count:desc&fields=artist,name,album,play_count&size=10&pretty'
Well, I love this Slipknot album…
Top 10 most albums per artist/band
This query ranks artists/bands by the number of albums – that I own, of course:
$ curl -d '{
"query": {
"query_string": { "query": "*", "analyze_wildcard": true }
},
"aggregations": {
"per_artist": {
"terms": {
"field": "artist",
"size": 10,
"order": { "artist_albums.value": "desc" }
},
"aggregations": {
"artist_albums": {
"cardinality": {
"field": "album"
}
}
}
}
}
}' 'localhost:9200/library/track/_search?search_type=count&pretty'
Shortest/Longest track duration
Shortest track:
$ curl 'localhost:9200/library/track/_search?q=*&sort=total_time:asc&fields=artist,name,album,total_time&size=1&pretty'
Longest track:
$ curl 'localhost:9200/library/track/_search?q=*&sort=total_time:desc&fields=artist,name,album,total_time&size=1&pretty'
Longest single album duration
curl -d '{
"query": {
"query_string": { "query": "*", "analyze_wildcard": true }
},
"aggregations": {
"per_artist": {
"terms": { "field": "artist", "size": 1 },
"aggregations": {
"per_album": {
"terms": { "field": "album", "size": 1 },
"aggregations": {
"album_duration": {
"sum": { "field": "total_time" }
}
}
}
}
}
}
}' 'localhost:9200/library/track/_search?search_type=count&pretty'
Finding this one has been a bit problematic: I’ve found the correct result, but the method is flawed.
The method should have been:
- Aggregate tracks per artist
- Sub-aggregate the aggregated tracks per artist per album
- Sub-aggregate the aggregated tracks per artist per album by summing their
total_timefield - Sort the results by the
total_timesummed value of each artist album
I’ve managed to do all that except the final sorting, because Elasticsearch is only able to perform “deep” metrics sorting on nested sub-aggregations when all nested buckets on the path to sorting metric are single-valued, and this is not the case here. The only reason I’ve got the correct result in my case is because there is completely unrelated to the aggregation results: by default Elasticsearch sorts results by the number of documents per aggregated bucket, and it happens that the longest album in duration is by an artist/band that also features the most indexed documents in my collection. The problem can be observed when looking beyond the first result, for instance with a top 10 of the longest albums:
curl -d '{
"query": {
"query_string": { "query": "*", "analyze_wildcard": true }
},
"aggregations": {
"per_artist": {
"terms": { "field": "artist", "size": 10 },
"aggregations": {
"per_album": {
"terms": { "field": "album", "size": 1 },
"aggregations": {
"album_duration": {
"sum": { "field": "total_time" }
}
}
}
}
}
}
}' 'localhost:9200/library/track/_search?search_type=count&pretty'
Then I figured out a simpler way – incidentally providing correct results – but I had to let go the “artist/band:album” relation:
$ curl -d '{
"query": {
"query_string": { "query": "*", "analyze_wildcard": true }
},
"aggregations": {
"per_album": {
"terms": {
"field": "album",
"size": 10,
"order": { "album_duration.value": "desc" }
},
"aggregations": {
"album_duration": {
"sum": { "field": "total_time" }
}
}
}
}
}' 'localhost:9200/library/track/_search?search_type=count&pretty'
Largest single album in tracks number
$ curl -d '{
"query": {
"query_string": { "query": "*", "analyze_wildcard": true }
},
"aggregations": {
"per_album": {
"terms": { "field": "album", "size": 1 }
}
}
}' 'localhost:9200/library/track/_search?search_type=count&pretty'
Top 10 longest combined music duration per artist/band
$ curl -d '{
"query": {
"query_string": { "query": "*", "analyze_wildcard": true }
},
"aggregations": {
"per_album": {
"terms": { "field": "album", "size": 1 }
}
}
}' 'localhost:9200/library/track/_search?search_type=count&pretty'
Conclusion
This exercise allowed me to extract interesting facts and trends about my tastes from my own music collection, and got me to know Elasticsearch a little better in the process. It’s been a fun ride :)